In a video created for Google Search Central, Google’s Gary Illyes tackles one aspect of the process of indexing webpages surrounding Canonical Selection. He began generally by explaining what the signals are in webpages to Google when he explained what a canonical is. He also discussed what the “centerpiece” of a page is and had a conversation about the moving policy towards duplication and, with it, a new way of thinking about duplicates.
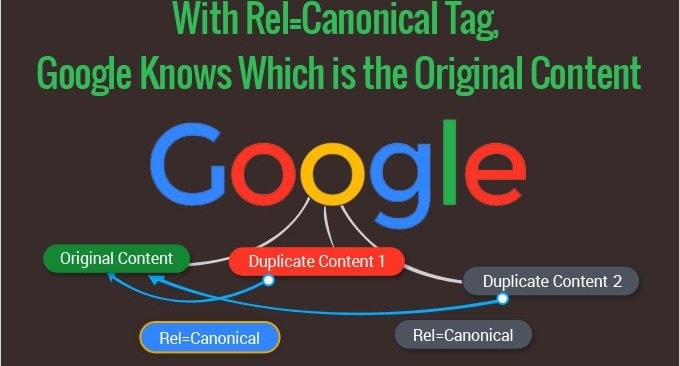
What is a Canonical Webpage?
A canonical page refers to the preferred version of a webpage with different versions, copies, or variations. It is taken to be the authoritative one, which would then indicate to search engines, like Google, what the main content should be for indexing and ranking purposes.
Canonicalization can avoid problems due to duplicate content and direct the search engine traffic to the desired version of the webpage. The address of a canonical URL is usually stated via a rel=\”canonical\” link element in a webpage’s HTML code.
Insights From Gary Illyes Regarding Google’s Crawling Priorities
Canonical can mean so many different things depending on the perspective: whether that’s from a publisher’s and SEO’s end of the search box or from Google’s. Typically, publishers proclaim what they believe is the “original” web page, whereas SEOs often look towards identification of what would be the “strongest” version for ranking.
Canonicalization seems very different when considered from a Googler’s perspective, and it’s well worth hearing what Gary Illyes says. Google’s official documentation on canonicalization refers to choosing a canonical as “deduplication”, listing five common causes that create duplicate pages on a site.
Five Causes of Duplicate Pages:
- Regional Variants: For instance, content tailored for both the USA and the UK, accessible via distinct URLs but featuring essentially identical content in the same language.
- Device Variants: For example, a webpage has both mobile and desktop versions.
- Protocol Variants: Such as the HTTP and HTTPS versions of a website.
- Site Functions: Like the outcomes of sorting and filtering functions on a category page.
- Accidental Variants: For instance, inadvertently leaving the demo version of the site accessible to crawlers.
Canonicals can be approached from three distinct perspectives, and there are at least five explanations for duplicate pages. Gary introduces another perspective on canonicals.
Signals play a crucial role in the selection of canonicals. Illyes gives an additional definition of canonicals, this time focusing on indexing, and exploring the signals used in the process of selecting canonicals.
Gary elaborates:
“Google determines if the page is a duplicate of another already known page and which version should be kept in the index, the canonical version.
But in this context, the canonical version is the page from a group of duplicate pages that best represents the group according to the signals we’ve collected about each version.”
Gary pauses to discuss duplicate clustering and subsequently resumes discussing signals shortly thereafter.
How to Avoid Duplicate Content: Best Helpful Tool for Bloggers
He proceeded:
“For the most part, only canonical pages appear in Search results. But how do we know which page is canonical?
So once Google has the content of your page, or more specifically the main content or centerpiece of a page, it will group it with one or more pages featuring similar content, if any. This is duplicate clustering.”
I’d like to take a moment to highlight that Gary refers to the primary content as the “centerpiece of a page,” which is intriguing considering Google’s Martin Splitt introduced a concept called the Centerpiece Annotation. Although Gary didn’t delve into the specifics of the Centerpiece Annotation, his insight sheds some light on it.
Illyes elucidates the meaning of “signals”:
“Then it compares a handful of signals it has already calculated for each page to select a canonical version.
Signals are pieces of information that the search engine collects about pages and websites, which are used for further processing.
Some signals are very straightforward, such as site owner annotations in HTML like rel=”canonical”, while others, like the importance of an individual page on the internet, are less straightforward.”
Duplicate clusters are consolidated under a single canonical page, as Gary elucidates. For each cluster of duplicate pages in the search results, one page is selected to serve as the canonical representation. Every duplicate cluster is associated with one canonical page.
He goes on to say:
“Each of the duplicate clusters will have a single version of the content selected as canonical.
This version will represent the content in Search results for all the other versions.
The other versions in the cluster become alternate versions that may be served in different contexts, like if the user is searching for a very specific page from the cluster.”
Variations of webpages present intriguing possibilities, particularly for ecommerce platforms, as the last part highlighted. It’s essential to consider because it can enhance the ability to rank for multiple keyword variations.
Sometimes, a CMS creates multiple pages for a product of different sizes or colors, for example. Such alternates could affect the description. When there is a variant page that closely matches the search query, Google may decide to include such variants in search results.
This consideration is important in that there can easily be a temptation to redirect noindex variant webpages just to prevent their indexing, fearing some keyword cannibalization problem, which is not even there. However, using noindex on variant pages can actually backfire. There are instances when such variant pages will be better positioned to rank for more nuanced search queries with colors, sizes, or version numbers different from the canonical page.
Key Insights on Canonicals to Keep in Mind:
Gary’s discussion of canonicals consists of a wealth of information, including ancillary topics related to the main content.
Here are key takeaways:
- The main content is identified as the Centerpiece.
- Google evaluates a “handful of signals” for each discovered page.
- Signals represent data used for “further processing” post webpage discovery.
- Certain signals, like hints (including directives), are under the publisher’s control. The rel=canonical link attribute mentioned by Illyes serves as an example.
- Other signals, such as the page’s significance within the Internet context, lie beyond the publisher’s control.
- Some duplicate pages can function as alternate versions.
- Alternate versions of webpages retain the potential to rank and prove beneficial for both Google and the publisher in terms of ranking objectives.
Would you like to read more about “Google On How It Chooses Canonical Webpages” related articles? If so, we invite you to take a look at our other tech topics before you leave!
Use our Internet marketing service to help you rank on the first page of SERP.
![]()